PaperReading_FUDGE
FUDGE: Fuzz Driver Generation at Scale
idea
基于libfuzzer面向C/C++ 自动化生成fuzzer
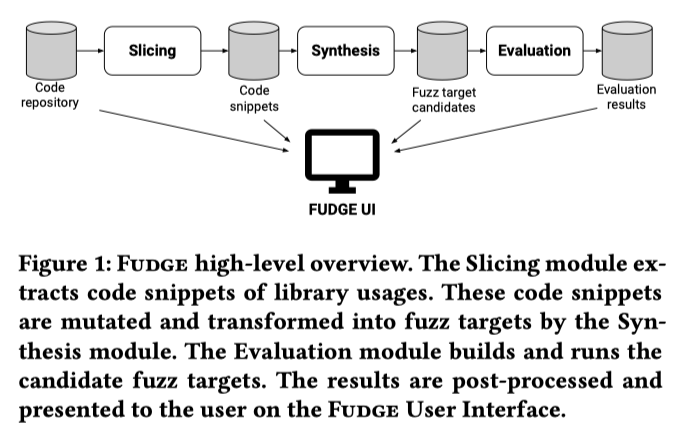
整个系统分为四个部分:切片阶段,targets合成阶段,target评估阶段,前端UI可视化显示前面三个阶段
前面三个阶段作为FUDGE后端,首先扫描代码库中目标libraries使用情况,提取interesting代码片段;
然后自动合成targets candidate;通过libfuzzer大规模运行targets candidate并对targets进行评估。
每个阶段信息都会实时输出到FUDGE前端。
涉及分析方法
涉及分析方法:程序静态分析,程序切片
系统架构
各阶段实现
Slicing stage
slicing阶段思路:
- ClangMR(较Clang相比,可大规模解析代码文件)扫描完整个codebase的source file
- 定位出target function,function内部调用的库函数可由外部传参
- 对function的AST进行切片,提取出相关语句
Slicing算法
将function的AST作为算法输入,将所有调用target library的语句作为seed 语句;
通过数据流和控制流分析,提取出seed相关依赖的语句.伪代码如下:

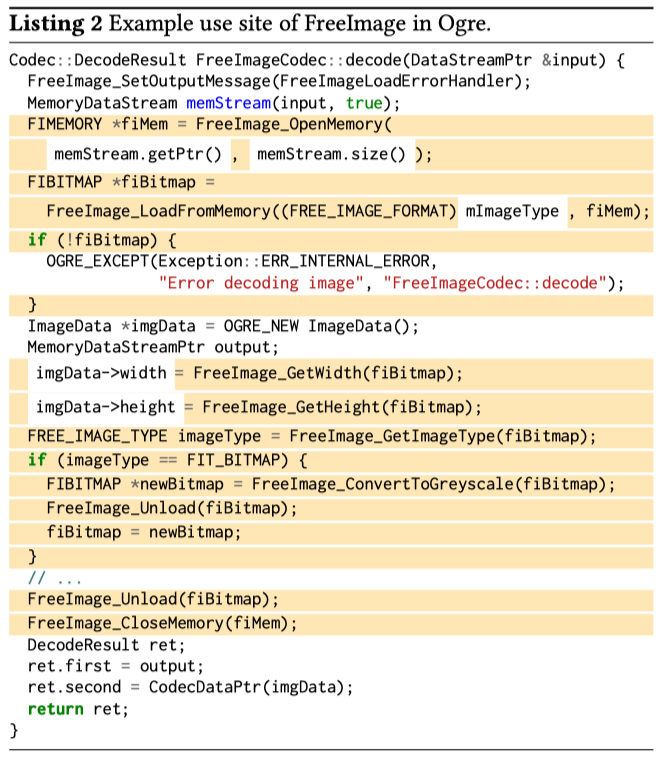
但有些语句不需要提取,包括不在function内部定义的变量,
如function参数(memStream.getPtr(),memStream.size())或成员变量(e.g., mImageType);全局变量;
不在function内部定义的function(e.g., reference to the FreeImageLoadErrorHandler function)
把这些不需要提取的部分用unknown X来标记。
黄色部分代表extract statements,白色部分代表ignore statemens
提取出来依赖语句之后,对函数重构,
首先剔除掉全局变量和常量,同时递归切片(指有调用关系的函数间切片),
并且将return语句都用return 0来代替(return 0代表target function成功执行).
重构后的代码如下:

最终我们从目标代码中提取到了code snippet,
但是我们还需要将code snippet中所需要的头文件和调用的其他库信息作为metadata(这些可以从Clang生成的AST了来获取)一同添加到code snippet中.
然后将code snippet提供给下一阶段Target Synthesis.
总结来说,splicing stage首先需要ClangMR来扫描source file;
根据调用的库函数有无可接收外部输入的参数,来确定target function;
生成target function的AST,进行切片;
在切片时,首先找出seed statements,然后基于seed statements进行数据流分析和控制流分析来提取statements,
并找出哪些statements是not be extracted;切片工作结束后,重构target function.
最终生成最后的code snippets.
Target Synthesis
将splicing阶段重构后的unknown参数具体化,由fuzzer来提供输入.下图为具体化unknown参数的对应类型

有很多种方式可以具体化unknown参数
比如有的API接收的参数类型为string,那么我们可以通过libfuzzer来生成input来feed给这个参数,
或者我们可以把string写入到一个文件里,然后把这个文件的路径(string类型)传递给这个参数,这样的话,就相当于可以生成两个target;
再比如说,我们不借助libfuzzer来给参数提供输入,而是通过定义局部变量的方式,将这个局部变量作为参数传递给API,这样也可以生成一个target;
再比如说,我们可以用0或者1来代替unknown X,这样也可以生成一个target。
下图所示代码为替换unknown X后的接口

为每个AST生成一个hash,并将这些ASTs的hash生成一个set,通过验证AST的hash来判断某个ast有无重写

如上述代码所示,在target合成最后环节,将提取到的ast作为输入,如果ast解析后还有unknown关键字,
那么就说明这个ast没有被重写(unknown X具体化),同时会通过ast的hash来记录ast的唯一性。
Target evaluation
将candicate target提供给libfuzzer并在规定的时间内运行,
可以去除掉一些产生误报或无效crash的target.
将interesting target保存到临时的repo,评估结果保存到数据库里.
启发式算法生成target(会生成非常多的target,但还需要我们自己去筛选哪些为valid target),
导致生成的target不一定是理想的target,
因此我们需要对每个library的API生成的candidate target进行排序和筛选.
valid target的要求:
the driver fuzzes the right API for the library
所谓right API,比如有这样的一个API,它需要提供参数来输入进来,
但是无论提供的这个参数值是多少,她都会返回一个固定的值,比如return 4.
那么这种API是完全没有被fuzz的必要,因此也无需为这个API生成target.再比如一些函数的参数条件要求比较严格.fuzzer随机生成的输入不太容易满足.
这种情况需要用户来手动筛选,是否需要保留这个target.the APIs are used correctly for the purpose of fuzzing
筛选策略:根据下面四个signals挑选candidate target
target可以成功构建
target自身正常运行
为corpus设置最小阈值
执行时可覆盖更多的路径
如果满足上述四个signals,那么就说明这个candidate target是可作为valid target
之后就是构建并运行valid targets来获取执行过程中的信息了。
首先build target and records构建状态和日志;
运行fuzzer并收集crash,在资源消耗和发现crash之间折中找出理想的运行时间,即规定时间内可以发现更多的crash;
收集harness如覆盖率信息,以及corpus minimization
需要注意的是,每个fuzzer都会通过沙箱隔离开来,保证每个fuzzer执行的独立性,可以避免资源占用.
比如fuzzer-A在进行写入磁盘操作时,可能会占用整个磁盘.那么通过沙箱隔离就可以为每个fuzzer分配对应的磁盘资源.
前端UI显示
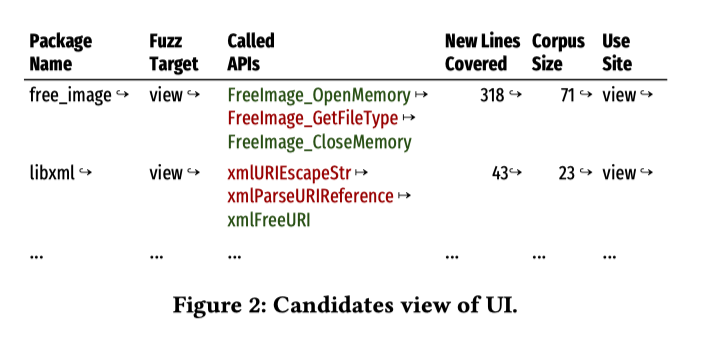

user packages: 依赖这个包的其他包的数量
existing targets: 当前调用这个库的API的target有哪些
candidate targets: 这个API所有的候选targets有哪些
两个区别: exitsiting代表当前由用户筛选后的targets;candidating代表生成的所有的targets.(由于没有开源,只是猜测区别是这样的.)
- public apis: 生成target的API有哪些

默认显示被其他包调用的APIs,重点关注实际使用的API.
显示API名称和接受的参数类型,点击API名称还可看到具体的函数定义
三种颜色代表了这个API的三种targets生成状态
绿色代表这个API当前已经生成了至少一个target
use sites: 以表格形式展示调用这个API的所有调用者
未来工作方向:
- 由c/c++扩展到其他的语言的target生成
- 基于单元测试的动态执行生成target
- 通过机器学习方式根据动态执行(覆盖率、语料库大小、crash数量)和静态执行(API名称、库的调用图)收集到的信息来对candidate target进行分类